Reinforcement Learning for Marketing: Lessons and Challenges
What is reinforcement learning (RL)?
In reinforcement learning, an “agent” can take different actions within an “environment.” Unlike many machine learning algorithms which involve only a single step, reinforcement learning is an iterative process: the agent sees a representation of the environment’s “state,” and based on that, takes some action over a series of discrete time steps. If the action results in a favorable payoff, the agent is rewarded, which helps it to learn about which actions lead to the best outcomes in different states. The feedback might be given to the agent right away after each state, or at the very end of the task. Regardless, the agent’s goal is to maximize their total long-term payoff, which means that actions can be taken at each step in a strategic manner, with long-term goals in mind.
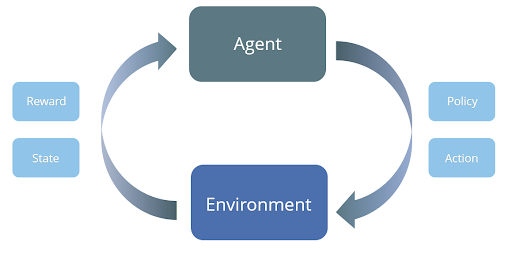
What does RL have to do with online marketing?
In conventional data-driven online marketing, the goal is to maximize some short-term reward: For example, to select an action (like sending a newsletter or coupon) that maximizes the chances of a particular goal metric (e.g. buying probability, clicks, expected additional profit, etc.) within a given timeframe.
In contrast, reinforcement learning methods aim to select actions that maximize the long-term reward. It could be that delayed marketing behavior would have a greater long-term impact on a customer - maybe showing a banner and later delivering a discount code will be more effective than giving the customer the discount directly, for instance. Such outcomes may be missed with a model that only considers short-term returns.
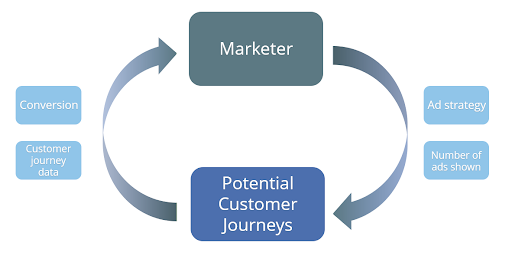
We can apply the RL framework to digital marketing with an example using Customer Lifetime Value (CLV). In a CLV analysis, the goal is to project how much revenue might be earned throughout a customer’s entire relationship with a company. So, it seems logical that a good CLV analysis should take a longer-term view to make accurate predictions about the customer over time in a dynamically-changing environment.
In such an example, the agent is the marketer, and the environment is the set of all possible paths along a customer’s journey. The possible actions available to the agent/marketer could be the number of ads to show to each customer, and at which point in time. At each time step the agent assesses the state of the customers, and makes decisions on how many ads to display, with the goal of maximizing conversions in the long-term.
One important distinction is the difference between “online” and “batch” reinforcement learning. Online reinforcement learning takes place in real time, with the strategy being continuously adjusted based on incoming data. In contrast, batch reinforcement learning functions in an environment where a larger batch of data is first collected, and the optimal strategy estimated afterwards. This can take place in an iterative process, where data is repeatedly collected and the strategy is adjusted.
Application
We attempted to apply a batch reinforcement learning approach to customer journey data. The action was the number of ads shown at a given point in time, and the reward was calculated by considering whether or not the customer converted, the cost of the ad, and the expected final reward. The rewards and transitions utilized by the model were stochastic in nature, since a customer's reaction to a given action is not deterministic.
The method employed for the estimation was Q-Learning, which, according to Wikipedia, “is a model-free reinforcement learning algorithm to learn a policy telling an agent what action to take under what circumstances. It does not require a model of the environment, and it can handle problems with stochastic transitions and rewards, without requiring adaptations.” Q-Learning can be combined with different deep learning (Deep-Q-Learning) or machine learning models such as random forests or gradient boosting. For this project, we utilized XGBoost (gradient boosting), as it delivers state-of-the-art performance for tabular data with a high level of interaction.
Results
The main take-away from this project was a series of learnings about issues one may face when implementing reinforcement learning techniques for customer data.
Batch Reinforcement Learning Poses Challenges
For most businesses, online reinforcement learning is unlikely to be feasible. Therefore, batch RL could be considered as a promising option - but it has some drawbacks:
- Some randomness in actions is necessary, otherwise the model is unable to estimate how different actions would influence the long-term reward. This randomness may be lacking in batch data where the actions were predetermined by former marketing campaign choices.
- It is challenging for batch reinforcement learning models to evaluate the reward of a newly-found strategy without applying it online, because Q-Learning tends to overestimate the rewards from “optimal” strategies in-sample.
- It is crucial for the feasibility of reinforcement learning-based online marketing that the state and environment can be observed and stored, and the action adjusted within a meaningful timeframe. This is challenging because there is inherent uncertainty about the customer’s state, which is a general concern in online marketing that has a particularly pronounced impact in reinforcement learning. For example, one does not always know if a customer actually received a newsletter (it could be in their spam folder), or if a banner advertisement was actually visible (if the customer uses an AdBlocker or didn’t scroll far enough on the page). This makes it challenging for the model to accurately determine the best action to take.
- To make marketing decisions in real-time, all data sources need to be integrated and available such that immediate adjustments to actions are based on recent data. With batch reinforcement learning, it is often not possible to implement the optimal strategy in time, even if one has clarity around the customer’s state.
Defining Time Steps and States is Inconsistent
Reinforcement learning necessitates defining discrete time steps in which to order the transitions from one state to another. In online marketing, these time steps are not always clearly defined. Some applications may be well-suited to using visits to an online webstore as the time steps, but in other cases there may not be an obvious choice for defining the transition into a new state.
Key Takeaway
While reinforcement learning is certainly an interesting and promising method, it seems unlikely to be implementable for any but the largest companies with the most advanced infrastructure given the current technological environment. Indeed, this may explain why we have not yet seen the widespread adoption of reinforcement learning for marketing to the same degree as supervised machine learning.