Building a Strong Data Science Team from the Ground Up
Business is changing as a result of the increasing quantity and variety of data available. Significant new opportunities can be realized by harnessing the knowledge contained in these data - if you know where to look. A data science team can help to bring raw data through the analysis process and derive insights that are critical in today’s technologically-competitive environment.
For many companies, however, building a data science team can be daunting: the field is technical, the roles are varied, and buzzwords are common. The article aims to help with navigating this process by touching on what kinds of positions exist, which skills are really necessary, where the data science team should fit in the larger organization, and how to consistently make sure you’re hiring the right people.
A data science team can be made up of many different specialities
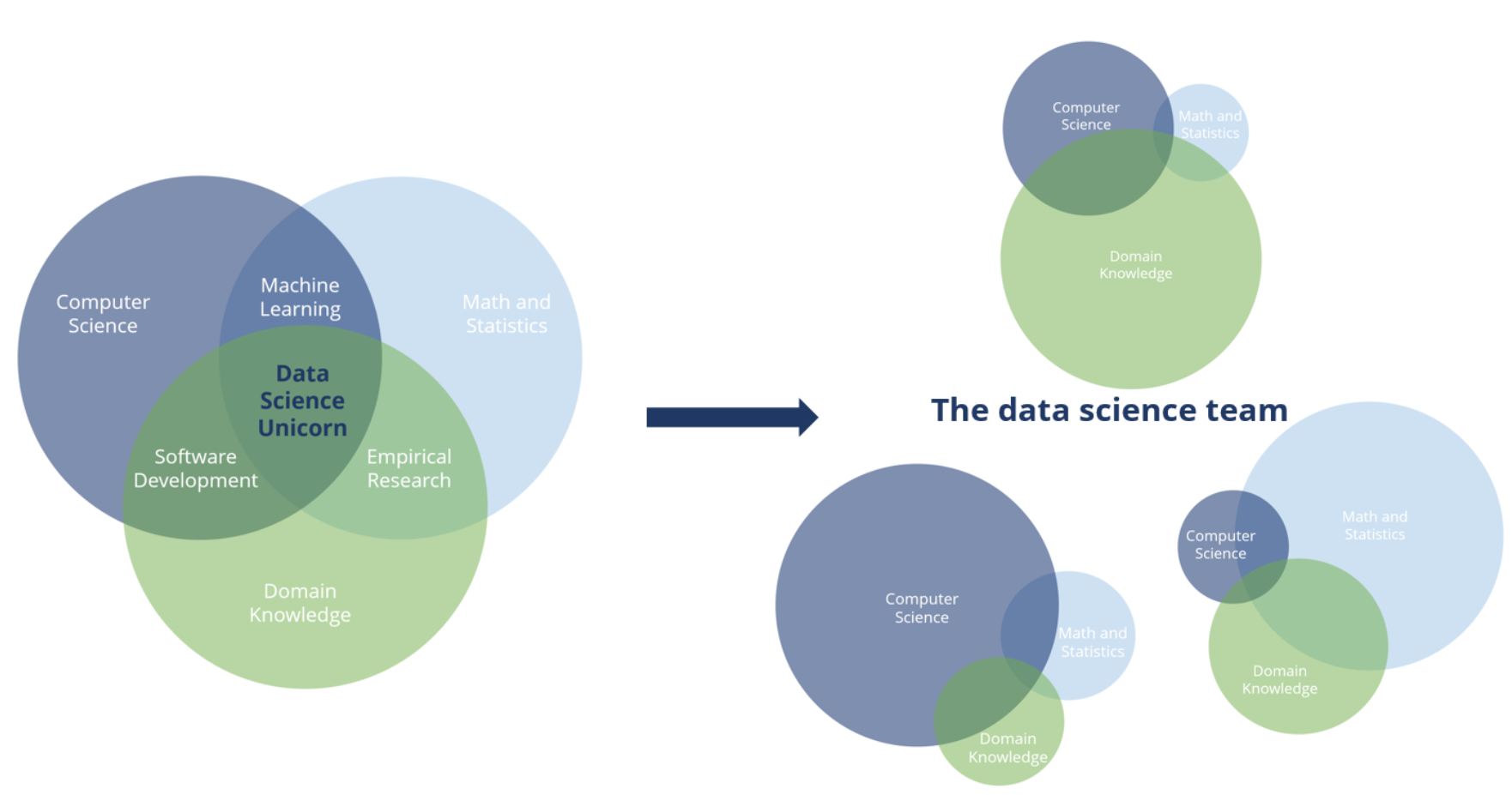
There is a common misconception that data scientists should be able to do everything necessary in a data science team. While data scientists do often have broad skills and knowledge, teams are more often composed of people with different areas of specialization.
For example, Data Engineers typically come from an IT background, and focus on building data infrastructure. Machine Learning Engineers are able to build a variety of machine learning models. Researchers or Statisticians are experts in statistical methods, and may come from an academic background. An Analyst or Visualization Expert is responsible for interpreting and presenting findings. Data Stewards are in charge of ensuring data quality, processes, and ethical handling. Data Scientists often have a wider combination of these skills. And of course, someone needs to have responsibility for managing a data science team effectively.
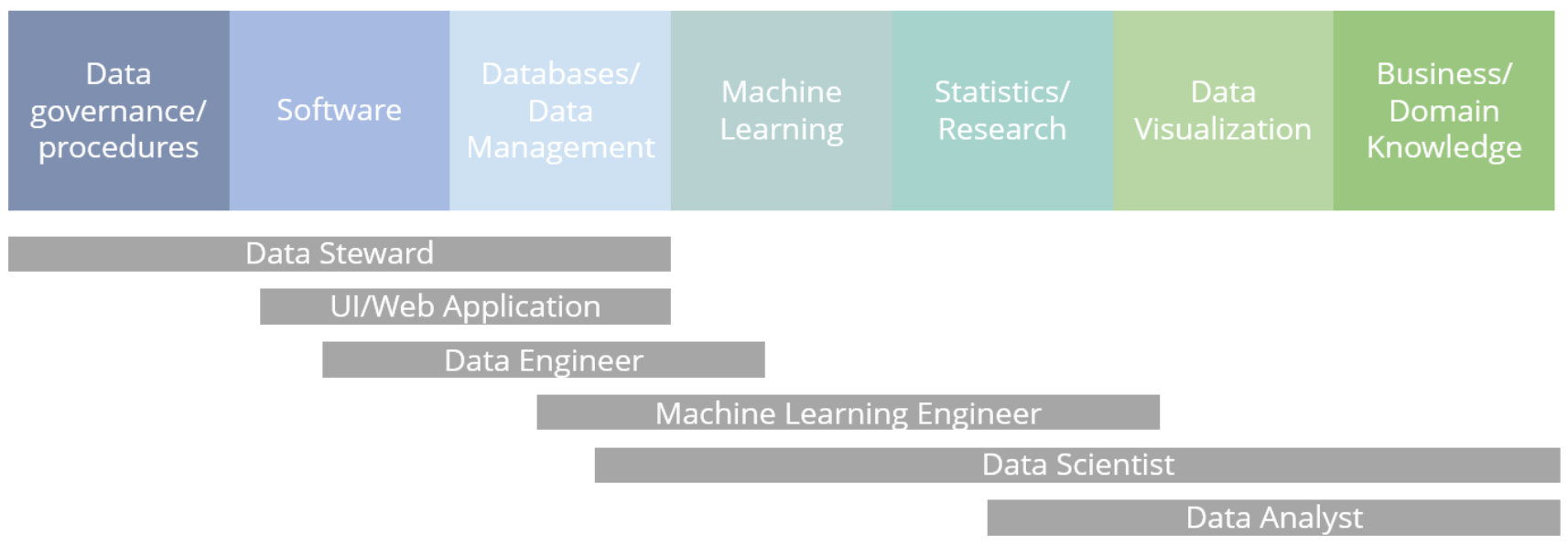
As the field continues to expand, new and more focused roles are always evolving. For example, DevOps Engineers and Solutions Architects are playing a larger role as the field matures.
Not all of these roles will be necessary for every project or business, but it makes sense to have people on your team with skills in all of these areas to at least some degree, such that together they can effectively tackle any challenge presented to them. Finding a single individual “unicorn” who can effectively represent the entire spectrum is unlikely, and often won’t result in the best outcome regardless.
Many skills are common among these positions. Beyond the technical, role-specific skills such as particular coding languages, statistical methods, or machine learning models, soft skills are a critical - and often under-appreciated - necessity for high-performing Data Scientists.
For example, excellent communication skills - both between departments and to communicate findings - are essential. Intellectual curiosity, an experimental mindset, and the ability to learn new concepts and tools quickly are also important. Attention to detail and respect for data quality are key. Some projects may also require business acumen or domain-specific knowledge.
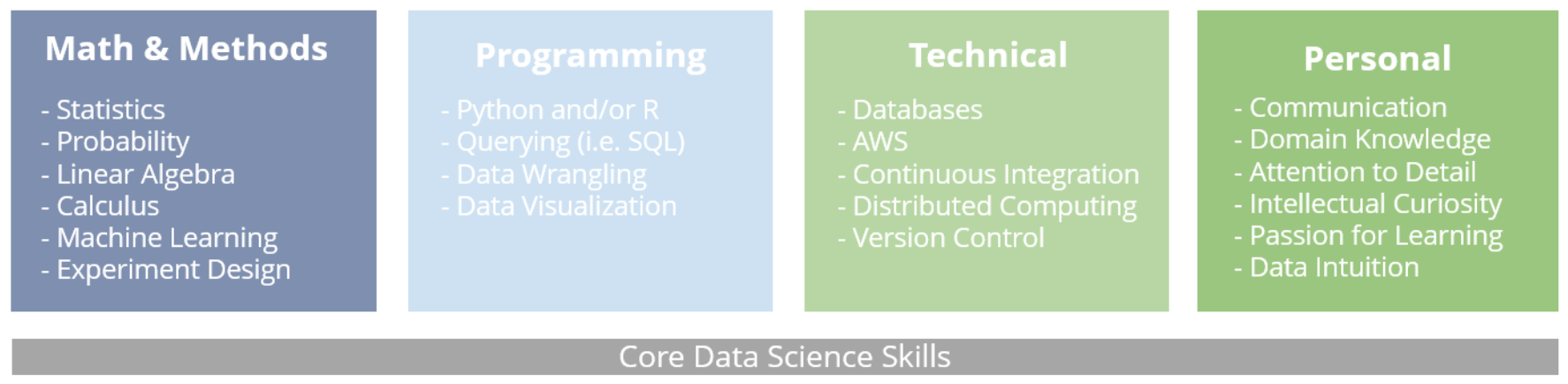
These soft skills will be important to different degrees depending on the project and team structure. The most important thing to consider when determining which skills to prioritize is really the specific needs of the business, and what business problem the data science team is intended to solve. Once a detailed analysis of this nature has been done, it becomes easier to formulate a concrete “wishlist” of skills that should be addressed throughout the team.
The importance of preparation
In addition to thinking about what kinds of projects the data science team would be responsible for, it’s important to consider the role that they will play in the organization. Conversations should be had with stakeholders throughout the company about what they hope to accomplish with data science, what is realistically possible to achieve, and what kinds of timelines should be expected. It is also necessary to ensure that organization-wide buy-in into the transition towards a more data-driven workstyle is in place.
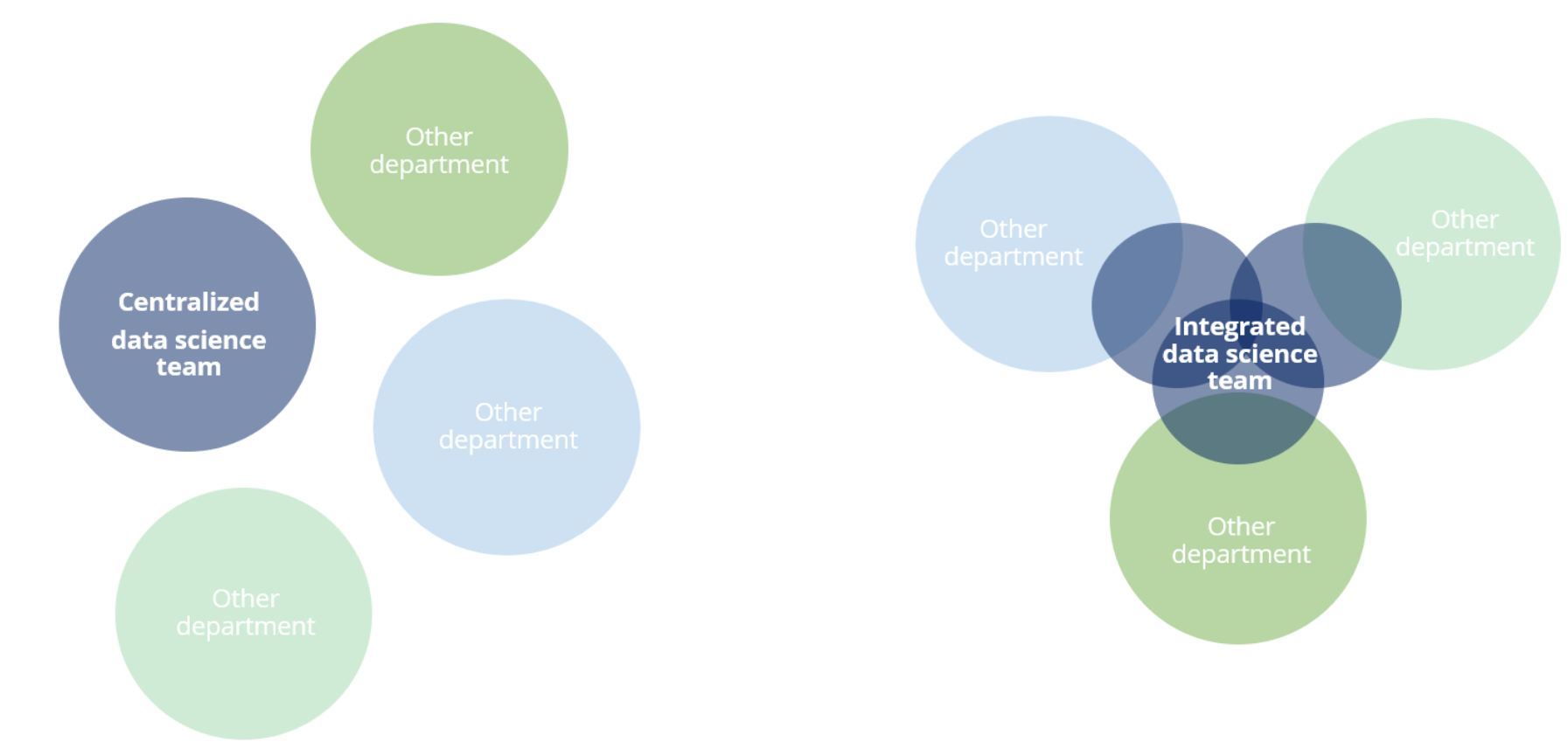
Beyond these efforts on a corporate culture level, the practical details of reporting structures are also necessary to define before onboarding and integrating a team. There are many potential structures successfully in use today, such as stand alone data science teams, embedded teams, integrated schemes, data science as an “internal consultancy,” and more.
Essentially, the primary question is whether it makes more sense for the data science team to be centralized into a single team reporting to one person, often the CIO or head of marketing, or not. The centralized option can increase autonomy and simplify systems and hiring, but may also result in a team that is siloed or far-removed from the actual efforts on a company-wide level. This can even lead to data science being seen as a support function, rather than an important ally and thought partner for driving the business forward in a data-driven way.
In contrast, a more decentralized model may have data scientists throughout many levels and departments within a company. These individuals could be hired by a central head of data science, or the departments themselves. This helps to align the goals of individual data scientists with the organization as a whole, but potentially at the price of autonomy, knowledge-sharing, and career development among the data scientists dispersed throughout the company.
Another major piece of preparation is doing a deep-dive into what data are currently available, or potentially available with some effort. Beyond ensuring that adequate quantities of data are available, and on the right topics, the real key is ensuring quality is in place. Data science insights are only as good as the data they are based on.
If it turns out that the data aren’t yet where they need to be, it may be worthwhile to begin forming a data science team by hiring a Data Engineer or Data Steward who can help clean up existing data and set processes in place to ensure proper data gathering techniques are applied moving forward, before bringing on anyone in an analytic capacity. In the long term this is a more efficient strategy, and one that can ensure insights from the data science team have the intended impact.
Hiring the right people
In the early stages of bringing data science more closely into the center of your business, it is likely that you won’t have a very clear idea of what, exactly, the data science team will encounter in terms of data or use cases. It makes sense, in this case, to hire with an eye for candidates with a broad spectrum of skills, rather than individuals that have a strong specialization in a particular field. They will be more equipped to learn new skills and tools on the job as they encounter unexpected challenges.
With that in mind, it is also wise to hire people with some prior experience early on, if at all possible. While students and newer-arrivals to the data science scene can absolutely be a valuable addition to the team, in the early days it is important that the new team can be anchored by at least one or two individuals that have some experience, so that everyone in the organization isn’t learning all at once.
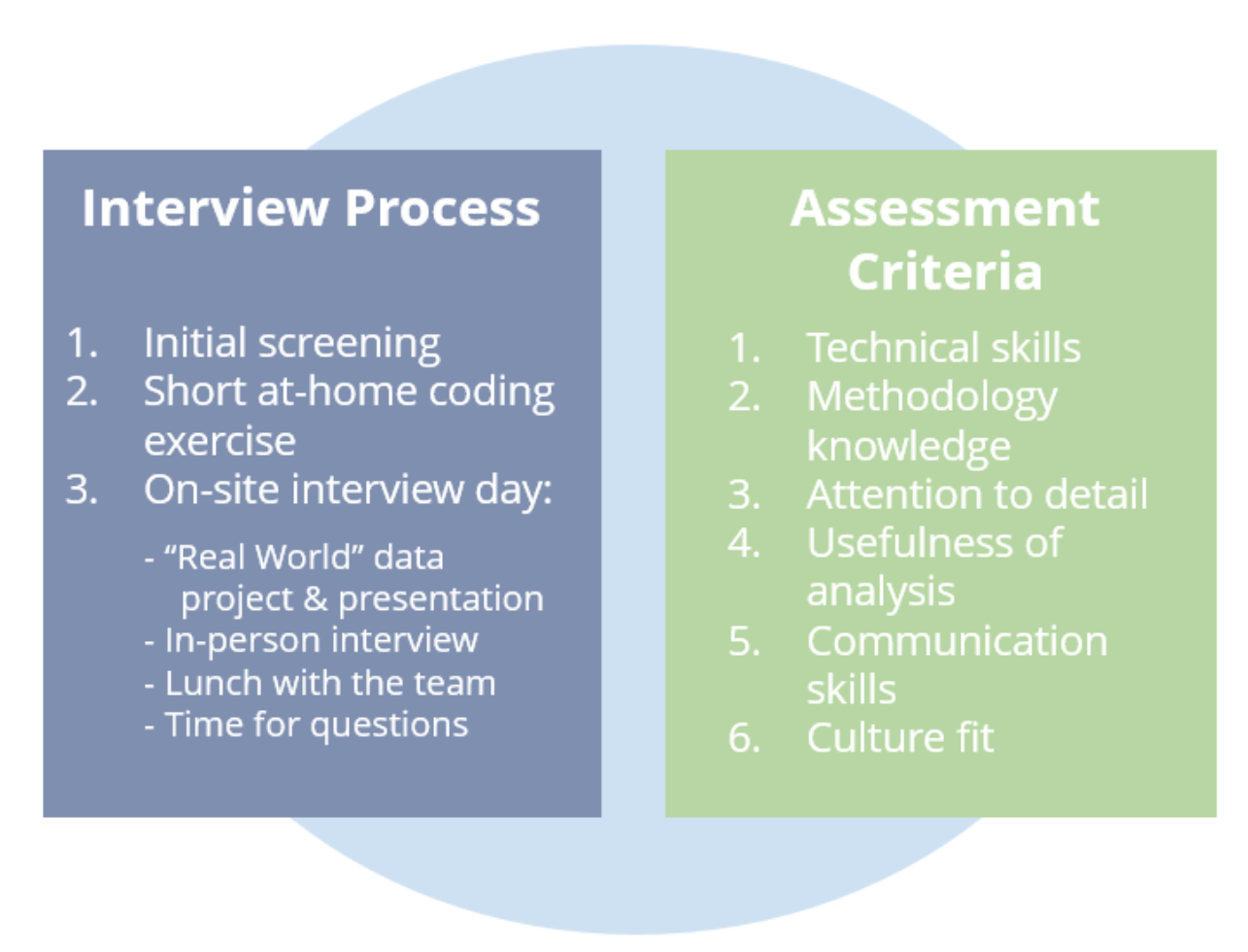
In terms of finding the right candidates, having a solid hiring process is key. This typically involves an initial coding exercise to ensure a baseline level of technical ability, an in-person interview to make sure they’re a fit culturally with the organization, and often a more involved data analysis project.
For example, candidates who seem particularly interesting based on their background and initial screening may be brought to the company for a data challenge, where they are presented with a dataset reflecting a real data problem likely to occur at the company, and given a day to examine the data, ask questions about the business case, create an analysis, and present their findings. This gives you the chance to learn a lot about a candidate, and for them to also get some insight into the kinds of tasks they would be responsible for and what it would be like to be a part of your team.
Since soft-skills are an often under-appreciated aspect of the ability to perform well in the data science field, bringing the candidate in for a longer project also provides an opportunity to grab lunch together with the whole team to make sure that it’s a good social fit, beyond just testing their technical skills.
When evaluating a candidate’s performance on a data project, some things to consider are:
- Technical skills: Was their code up to standard (i.e. clear, flexible, scalable, etc.)?
- Methodology: Did they build a statistical or machine learning model? If so, was it appropriate, and were the results sound?
- Were they detail-oriented? Did they examine the dataset before working on it?
- How were their communication and data-storytelling skills?
- Did they ask appropriate questions to try to get an understanding of the business case and application?
- Were the results useful to the business?
Again, it’s important to keep in mind that nobody will be an expert in all areas, but a solid candidate should be able to explain the problem, their approach, and identify areas for future improvement. If they acknowledge a lack of proficiency in a particular area, this is likely positive - knowing the limits of one’s knowledge shows a realistic understanding of how much there really is to know in the field, and ideally the desire to keep learning.
Throughout the process of building the team, an important question will be how well this person would expand or complement the knowledge and skill set of the existing team, and whether they offer a new point of view. Emphasizing diversity of background, expertise, and even personal experience can prove valuable when faced with a new analysis challenge.
Getting started
It is important to begin with manageable projects in the early stages of building the team, if at all possible. For example, augmenting an existing workflow through data science can help to build trust throughout the organization and help the data science team to identify gaps in knowledge, data availability, or internal systems. A few modest projects offering incremental improvement can be a valuable proof of concept and learning opportunity before investing significant time and resources into a more complicated project, particularly since it is possible that such an endeavor will end up being unattainable if baseline data and systems turn out to be initially flawed. From there, larger and more impactful projects will become a core part of the data science team’s functionality, grounded in a strong baseline.
While it can seem overwhelming at first, the benefits of having a talented, diverse, and well-integrated data science team are immense, and in the context of quick and ongoing technological change, will likely only increase in the coming years. The key is to emphasize preparation and strategy to build the team with intention, and to hire with an eye for creating a well-rounded team that can help to move the business forward with data.